

�����ֹ��������ɭ��ۣ�ͬһ�����ݼ������֤��������ȫ�෴��



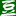

����һ���������������
������С������Ҹ��ط���һ�٣��������Ҳ�����ѡ������ִ���ݡ�
���Ǻ�������“������������”�����������С�ڵ��������������ݡ�
�㷢�֣�����ȥ����Ҳ��������ֹ�Ȼ����һ�Ҹߡ�
��������ⲻ�ѵ�ʱ�����С���������TA�ķ��֣���һ�Ҳ��������ָ��ߡ�
����զ������?Ī��������վ�����ݻ������˲���?
��ʵ�ϣ�������С��鶼�ǶԵģ�����ֻ���ڲ�֪�����е���������ɭ��۵Ĺ�ơ�
������ɭ����У��ݿ���ͬʱ�Ⱦ������ָ��û����������Խ��ͺ����Ӽ����ķ��գ�ͬ�������ݼ��ܹ�����֤��������ȫ�෴���۵㡣
��������ϳ�ȥ��ͣ����С���Ҳ����ֵ��������������˵�ͳ������
����ɭ���ָ���ǣ����ݼ�������ֵ����������ݼ��ۺϳ��ֵ������෴������
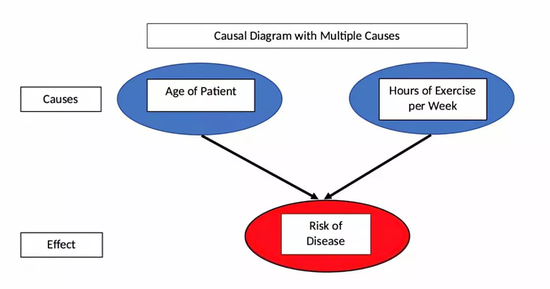
����������Ƽ��������У������ͨ�������Ժ�Ů�Ը�������֣�Ҳ���Կ���������֡�����ͼ��ʾ��
Carlo’s �����Ժ�Ů���Ƽ����϶�Ӯ�ˣ���ȴ�����������Ƽ�����!!!
ͼ����������ر���������������ÿ������ʱ�������ʾCarlo’s ��ʤ�������ϲ����ݺ��ȴ��Sophia’s ��ʤ!
����ô������?������������ڣ�ֻ�鿴�����������ݵİٷֱȻ���Ե������Ĵ�С��Ҳ���������ߵ�������ÿ���ٷֱȶ����Ƽ��û��������Ӧ��������������õ���Carlo’s �и�������������ߣ���Sophia’s �и����Ů�������ߣ���˵�����ì�ܵĽ����
Ҫ��ش��ȥ�ļҲ��������⣬������Ҫ���������Ƿ���Ժϲ��������Ƿ�Ӧ�õ������ǡ������Ƿ�Ӧ�úϲ�����ȡ�������ݵ����ɹ���——�����ݵ����ģ�͡�����һ�������У����ǽ�������һ���庬���Լ���ν������ɭ��ۡ�
����Է�ת
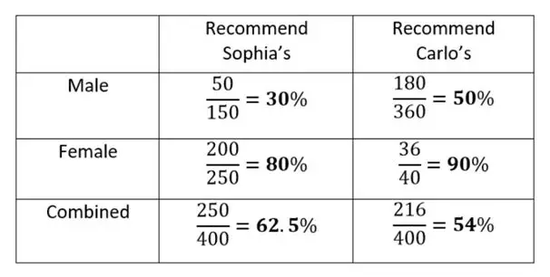
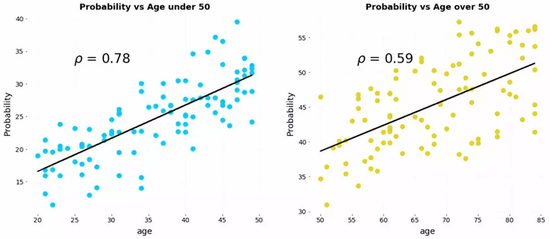
����ɭ��۵���һ����Ȥ����������ڣ��ֲ������ݱ��ֵ�����Է������������ݱ��ֵ�����Է����Ȼ�෴����������һ��������ӡ�����������ÿ���˶�Сʱ�������黼��(�ֱ�Ϊ50�����º�50�����ϵĻ���)�������յĶԱ����ݡ������Ǹ����˶������뻼�������Ե�ɢ��ͼ��
��������ֲ��Ļ�������ÿ���˶�Сʱ���ݹ�ϵͼ(��ࣺС��50�꣬�Ҳࣺ����50��)
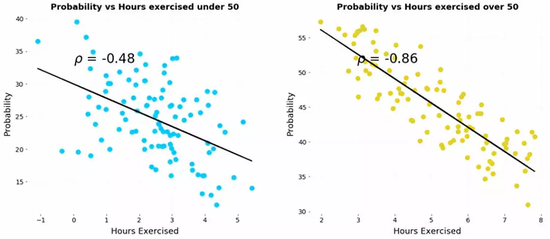
��ͼ�����ǿ�������ؿ������ݸ���أ���������ÿ���˶��������黼�����ʵķ��ս�����ء����������ǽ����ݺϲ���һ�������������ǵĹ�ϵ��
�ϲ���Ļ��������˶�����ͼ
�������ȫ��ת��!���ֻ��������ͼ��������ǻ�õ������Ľ��ۣ��˶������˻������գ��������Ǵӷֲ�����ɢ��ͼ�еõ��Ľ�����ȫ�෴��
�˶���μȼ��������Ӽ���������?��ʵ����Ȼ��Ҫ��Ū����ν�������ۣ�������Ҫ�����ݵ����ɹ���������չʾ�����ݺ�ԭ��——��ʲô��������Щ�����
������
Ϊ�˱�������ɭ��۵��µó������෴�Ľ��ۣ�������Ҫѡ�����ݷ��黹�Ǻϲ������������ƺ��ܼ�������Ӧ����ξ���?�𰸾��������˼������������β�����?�����ڴ˻����ϣ���Щ����û������������Ӱ����?
���˶��뼲���������У�����ֱ�۵�֪���˶�����Ӱ�췢���ʵ�Ψһ���ء����ﻹ���������أ�����ʳ���������Ŵ����صȡ����ǣ�����ͼ�У�����ֻ�����˷��������˶�ʱ��Ĺ�ϵ�����������������У����Ǽ��輲�������˶�����������ġ�������ļ������ʵ����ģ������ʾ���ǵĹ�ϵ��
�����ʵ����ģ��������������
�����д������ֲ�ͬ�������뷢������أ������ڻ��ܺ�����ݣ�����ֻ�۲��˷��������˶�ʱ��Ĺ�ϵ��ȴ��ȫ�����˵ڶ�������——���䡣������ǽ�һ������������������Ĺ�ϵ�����ܷ��ֻ��ߵ������뷢����ǿ��ء�
������ֲ��ķ������������ϵͼ(��ࣺС��50��;�Ҳࣺ����50��)
���Ż�����������ӣ���/�������ķ�����֮���ӣ��������ʹ�˶�����ͬ����£��곤��Ҳ�������߸�����������ˣ�Ϊ�˵��������˶��Լ���������Ӱ�죬����ϣ�����ֻ��ߵ����䲻�䣬���ı�ÿ���˶�����
һ��ʵ�ֵķ�ʽ�ǽ����ݷֳɼ��飬ͨ�����ַ�ʽ�����ǿ��Կ��������ڸ��������飬�˶����Խ��ͻ������ա�Ҳ����˵���ڿ����������ص�����£��˶���ͻ�������ء������������ɹ��̺�Ӧ�����ģ�ͣ����ǿ���ͨ�����ݷֲ������Ƹ������ؽ������ɭ��ۡ�
˼����Ҫ�ش������Ҳ���������ǽ����ۡ��ڲ����������У�������֪���ļҲ������п������Һ�С��鶼���⡣��Ȼ���˲������������������ܴ�����������Ӱ�����ۣ�����û����ЩDZ�����ݵ�����£�����ϣ�����������۽����һ������������ƽ�����������������£������ϲ�������ݸ������塣
���˶��뼲����������Ҫ�������������ǣ������Լ��Ƿ�Ӧ�������˶������ٸ��廼������?�������ǵ�������ߴ���С��50/����50����������(���ﲻ������������Ϊ50������)��������Ҫ���ݾ�������۲��Ӧ�������飬�������������������飬���۶���ʾȷʵӦ�ö������
�����������ɹ��̣�Ҫ�ش����ǵ���������Ҫ�IJ������ǹ۲����ݱ������⼸����ʾ������ɭ�������ؼ���һ�㣺���ݱ����Dz����ġ����ݴ�����������ȫ�۵ģ��ر��ǵ�����ֻ�����չʾ��ͼ��ʱ��������Ҫ�����Ƿ���ȫò��
���ǿ��Գ��Թ۲�ø�ȫ�棬ͨ��˼��ʲô���������ݣ�������Щδչʾ���ض����ݲ�����Ӱ�졣��Щ����Ļش���ʾ������ʵ��Ӧ�õó���ȫ�෴�Ľ���!
��ʵ�����е�����ɭ���
����ɭ���������һЩͳ�Ƹ��ͬ������������Ϊ�����Ĵ����۸������ʵ�����л�ʵʵ���ڵط�����
��ʵ�ϣ��Ѿ��кܶ�����������ɭ��۰����ˡ�
����һ�������ǹ�����������ʯ����Ч�������ݡ�����������Ч����������ݣ�A�Ʒ����������ִ�С������ʯ��Ч�������ã����ǽ����ݺϲ����֣�B�Ʒ���������������Ч���š��±�չʾ�˿����ʣ�
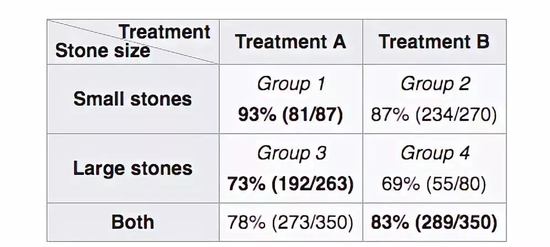
��������ʯ������
����ô������?�����ۿ������漰���רҵ֪ʶ���������ɹ��̣�����˵���ģ�ͣ����������С��ʯ����Ϊ�����صIJ�֢����ôA�Ʒ����B�Ʒ����Ĵ��ڸ�����ˣ�����С��ʯ��ҽ���dz��Ƽ�B�Ʒ������ڲ��鱾��Ҳ�����أ���˲��˿�����Ҳ�ϸߡ����������صĴ��ʯ��ҽ���dz�ѡ�ô��ڸ�����ЧҲ���õ�A�Ʒ�����ȻA�Ʒ��������Щ��֢ʱ���ֵø��ã���������������أ�����Ŀ����ʻ��DZ�B�Ʒ�Ҫ��һЩ��
��������ʵ�����У�����ʯ�Ĵ�С������˵��֢�������ԣ�����Ϊ��������;�����Ա���(���Ʒ���)�������(������)����Ӱ�졣���������ݱ����ǿ������������ӵģ������ǿ��������������ϵͼ�У�
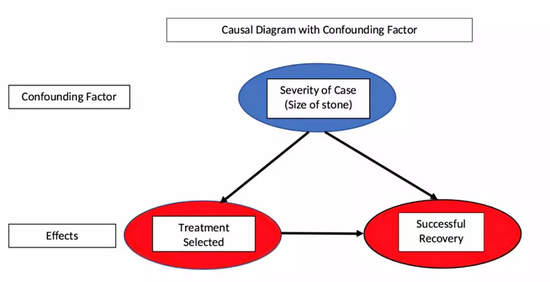
���������ӵ������ϵͼ
��������еĽ���������ʣ��ܵ��Ʒ��ͽ�ʯ��С(��֢������)��˫��Ӱ�졣���⣬�Ʒ���ѡ��ȡ���ڽ�ʯ�Ĵ�С���Ӷ���ʯ��С��һ���������ӡ�Ҫ�ҵ����������Ʒ�Ч�����ã�������Ҫ���ƻ������ӣ����з���Աȿ����ʣ����ǶԲ�ͬ��Ⱥ�����ݽ��мϲ������������ǵó����ۣ�A�Ʒ������㡣
����������������������⣺��С��ʯ���ԣ�A�Ʒ�����;����һЩ�Ĵ��ʯ����Ȼ��A�Ʒ����š���ˣ����۽�ʯ�Ĵ�С�̶ȣ�A�Ʒ���������——��۽����
�ϲ�������ʱ�����ã�����Щ�����ȴ����ʵ��������˸��š�
֤��һ���۵㣬����֤�����෴�Ĺ۵�
����ɭ���Ҳ�������ǵij��ü�����

���������֤չʾ�ˣ�����ɭ��������֤�������෴�����ι۵�ġ�
�±��������ڸ�����ͳ��1974~1978��������У�����ÿ��������Ⱥ�������˼�˰�������ڼ�ȫ���Ե�˰�ն����������ǡ�����չʾ���£�
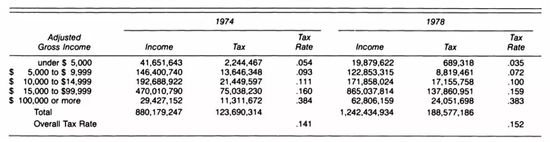
���и���˰�ʶ��½��ˣ�������˰����������
���ǿ��������ؿ���1974-1978��䣬ÿ����˰�����˰�ʶ������½���������˰��ȴ�����ˡ����ڣ�����֪������ν����ۣ�Ѱ��Ӱ������˰�ʵ��������ء�����˰�ʲ�����ÿ����˰����Ӱ�죬��ȡ����ÿ����˰����Ŀ���˰���������ͨ������Ӱ��(���幤������)��1978���и���������������˰�ʵ�˰�����䣬����������ϵ�˰�ʵ�˰�����������½����������˰���������ǡ�
�Ƿ�Ҫ�ϲ����ݣ�ȡ�������������ɹ���֮�⣬�������������˽�ʲô���⣬�ֻ��������ǵ����ι۵㾿����ʲô���Ӹ��˽Ƕ���˵������ֻ��һ�����壬���ĵ����ڸ��˵�˰�������ڵ�˰�ʡ�Ҫ�������1974�굽1978��䣬��������˰������û������������ҪŪ�������˰�������˰���Ƿ����˱仯���Լ����ǵ�˰�������Ƿ���һ���µ������С���������˰����������Ӱ�죬�����ű��������ֻչʾ������һ����
����ɭ����к�����
����ɭ��۵���Ҫ����������ʾ�����ǿ��������ݲ���ȫò�����Dz���������չʾ�����ֻ�ͼ����������Ҫ���������������ɹ��̣��������ģ�͡�һ���������������ݲ����Ļ��ƣ����Ǿ��ܴ�ͼ��֮��ĽǶ����������⣬�ҵ�����Ӱ�����ء������ݿ�ѧ�Ҳ�û��ѧϰ���˼����ģʽ��������˼��ģʽ�����Ƕ���������Ҫ����Ϊ���ܷ������Ǵ������еó�������ۡ�����ʹ�����ݣ�������Ҫ���þ����ҵ��֪ʶ��������ר��ѧϰ�������õؽ��о��ߡ�
���⣬��Ȼ���ǵ�ֱ��������������������Ϣ��ȫ�������ֱ�����ǻ�����������ڶ�ֻ��ע��ǰ�Ķ���(����������)���������������Զ��ٻ���˼��ȥ�ھ�����Ķ�����������Ҫ�����ֱ����ֻ���̬�ȣ������ǵ�������������Ӫ����Ʒ����Ŀ�ƻ�ʱ��
������һ�������������������ܱ�����������ʵ��Ҳ�ܱ����������Ƿǡ�
���α༭��������

?�������������Ľ��������߸��˹۵㣬�뻷�����ƾ��ء���ԭ�����Լ����г������ֺ�����δ����վ֤ʵ���Ա����Լ�����ȫ�����߲������ݡ����ֵ���ʵ�ԡ������ԡ���ʱ�Ա�վ�����κα�֤���ŵ������߽����ο����������к�ʵ������ݡ� |




- ��С�Ƴ������٣����������г���ϴ��?
- �����ձ�ŭ�����ٲ����Σ������Ї���µ���50��
- �����̷���ʵʩ�ڼ� �Ժ��Dz����Ҳ��Ŵ�����?
- ������ý����¡�ϴ�塱��ҵ����ǧ��10Ԫ ����ͷ����
- �����ձ�ʹ����˯�еĴ�ѧ�����㲻ʧҵ����������
- ������ҵ��������Ա�ۿ������ ���վ�Ӫ����Ƶ��
- ���أ����������ף����ر���
- ���ز�������ʴ�Ϸ��ӳ��������ڡ�
- ���ӳ�Ϯ�������֡��յ��������µ� ������ͱ�ˡ�����
- �������ǣ�άȨ�ߴ�����50�� ��������1.2��
- ǧ��Ҫ������Ȧ��������ɼ�
- �������ڣ��ٳ����й���ʷ�����˽���������
- ��ʷ������Զ�����ܿ����Ķ���!
- ����ǰ�������� ��Ļ�����?
- ����ͻ������Ϣ��һ��������������!
- ���µ����������ߣ���������ҵ

- ��ʤ�� һ��ʱ���ķ���
- ���ԣ���Ժ��Ժʿ���¼
- ��Щ������������ҵ����
- 2013��ӱ�ʡʳƷ��ȫ������ʯ��ׯ�����
- 2013������ӱ�ʡ���շ�����̳
- 2013�궬������˹��̳
- 2012��ʮһ���й���ҵ�������
- �ӱ��ƽ���������Ȧ��������ͬ��ʱ��
- �ӱ��غ���չ����Ϊ����ս�ԣ��й����õڡ�
- 2012�����Ľ죩Ǩ��������
- 2012�Ϻ�����ģ�ش����ӱ�����
- 2012�ӱ���ǿ��ҵ��������Ұ�
- ��ʮ�����ɽ�մɲ�����
- �ӱ�ʡ��������ҵ�ص��ƹ㵥λ




CopyRight © 2002-2011 �������ƾ���
HBHCJ.CN, All Rights Reserved.Ͷ�����ߣ�0311-85089452 Ͷ�����䣺hbhcj@sohu.com
��ICP��11028489�� ��������13010202001473��
